A journey of Terraforming Azure PART 1
Table of Content
- Introduction
- Before automation
- First try
- Registry erzats
- Pipeline templates
- Second Attempt
- VCS workflow
- Conclusion
1- Introduction
Few years ago, as I started discovering cloud along with Infrastructure as Code, I had trouble understanding what everyone was talking about with CI/CD pipelines for Terraform. I had a rough idea of how it was supposed to work for application deployment, but struggled to understand how it worked. This piece will tell you the story of how, as I slowly progressed using Terraform, I iteratively improved my provisioning workflow, from my local laptop to azure pipelines.
This is the first article of a series. We will draw the high level concepts in this first post, before diving into each solution I came up with in the next ones.
2- Before automation
We talked before about the Terraform workflow. See diagram below:
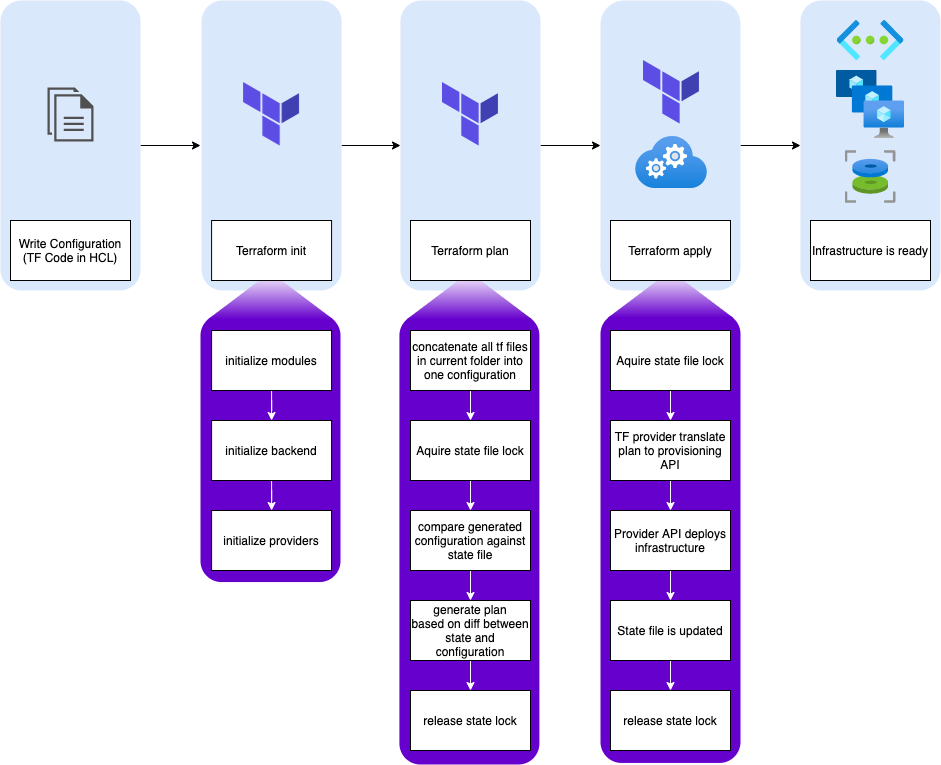
This is the foundational workflow. So before even trying to automate, I was using this very workflow, locally, with a local state. But as we also discussed before, local state can only get you so far, and has to be replaced by a remote backend to enable resilience and collaboration.
This was the only reference I had on how to run Terraform. But how to get from running this locally to this mogical pipeline thingy that was suppose to automate everything?
Well, I first had to understand what it was exactly that we called azure pipelines. To make it simple, it’s a collection of tasks organized in jobs and stages. These tasks can be a number of things like bash scripts, powershell scripts, or packaged binary tasks like docker build, push, etc. This process is setup by writing yaml files describing all the workflow. Finally, the pipelines are programmatically run on some ephemeral compute environment (i.e. VMs or Containers). In case of Azure Pipelines, this compute is called pipeline agents. We’ll leave it as that for now, but agents are also a topic on their own with Microsoft-hosted vs Self-hosted, managed-vmss…
3- First try
Now that I understood the pipeline and agent concept, yes I can be a bit slow sometimes (!), I started thinking how to implement the basic TF workflow with it. Like any other IT professional I had a look at blog posts and forums like good ol’ Stackoverflow to steal find some examples. ^^
And my first iteration was to simply replicate terraform workflow in pipeline agents/runner: validate->plan->(check)->apply
And so I found some people’s work on blogs and even youtube, to eventually make it work. However, everything I found was packaging the whole process in one stage. Ah. Remember I was telling you about how pipeline tasks were organized? Well the highest level is stage, which contains job(s) which in turn contains tasks. Apart from hierarchy, this also as implications in possible paralelism among other things.
Back to my issue.
When you look at Azure pipelines’ UI, a stage will be represented as rectangle. Like this:
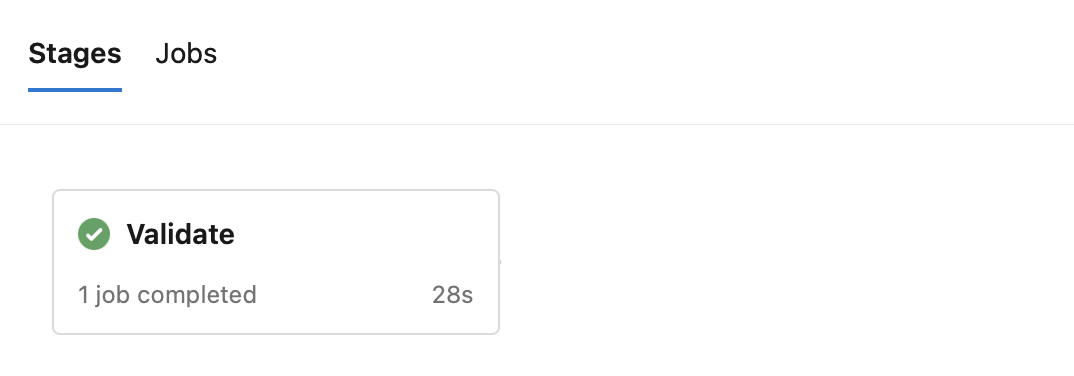
I’m a visual guy. This just doesn’t cut it for me.
Sure, when you click it, you have access to all tasks within the stage (within the job within the stage actually), and look at terminal output of each task, but I don’t like to click that much haha.
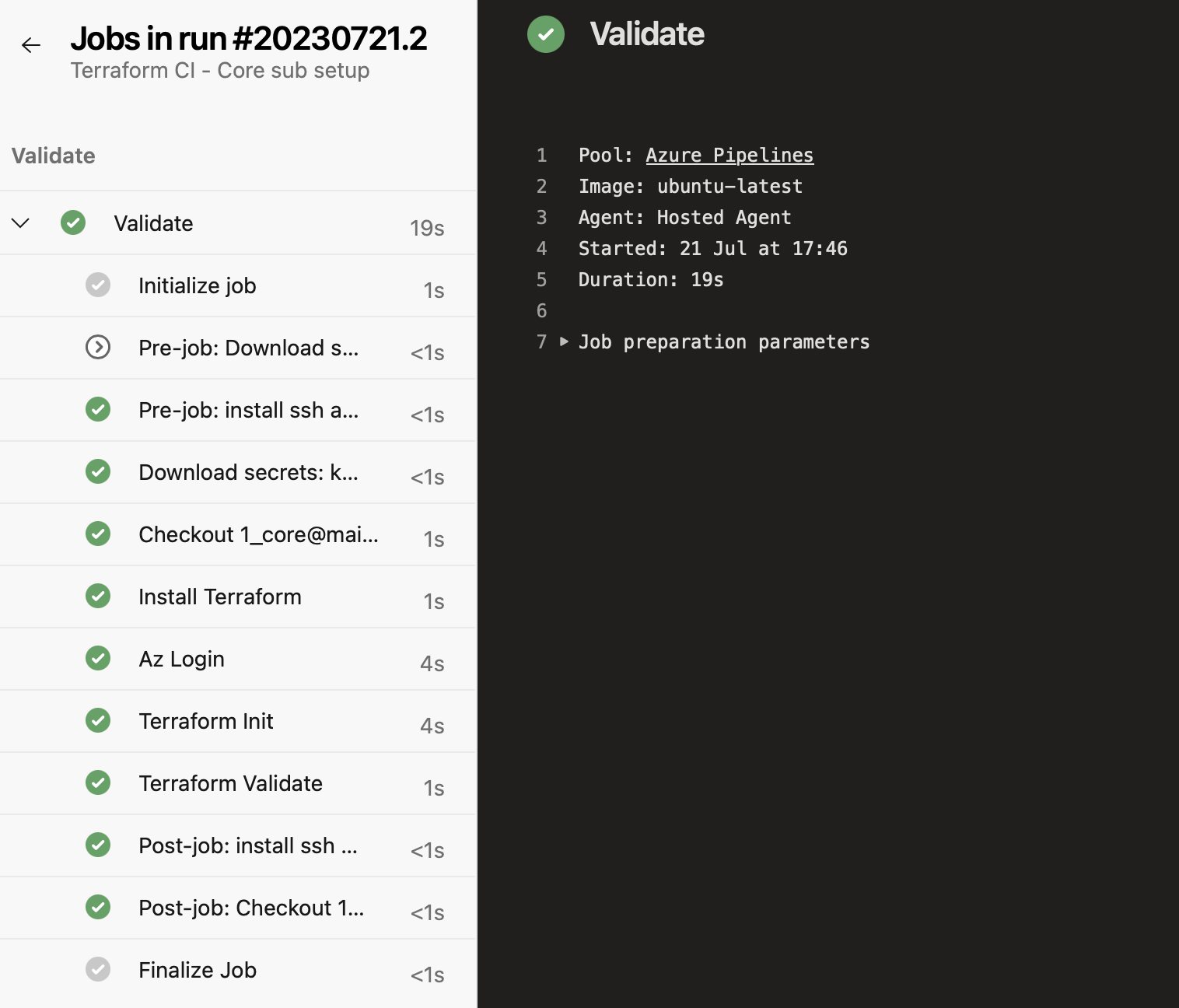
Basically, to get a visual representation of the workflow, I had to split each terraform stage into, well an azure pipeline stage. Now that I write it down, I feel kinda stupid not realising it from the get go. Anyway. I left aside the job as I didn’t really need it. I would run only one job per stage, and multiple tasks per job.
However…
It failed miserably leaving me wondering why. I mean, I could have read the documentation, surely it’s written somewhere… As it happens, while tasks in a same job are run in the same shell, jobs are not (they can actually be run in parallel on multiple agents), and so variables are not pass from stage to stage. Talk about an important detail…
So back at it with proper env variables setup, repeated on each stage (we’ll get into more details on the following article) and here we are:
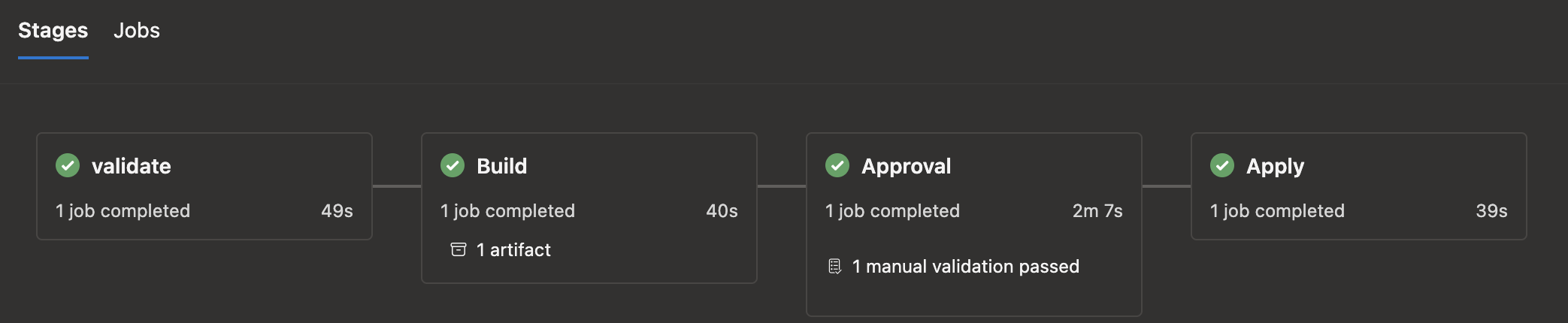
Much better if you ask me!
One little thing I had to sort out was how to approve the plan. Best thing I could find was some preview or experimental task at the time (can’t really remember), which allowed me to have a manual validation with an email notification. Pipelines are not interactive, they show you stuff happening on the agents running them, but you can’t input anyhing in the process, like, say, a convenient yes or no after the terraform plan?
I was still the main (only?) contributor at the time, so didn’t have to bother thinking about team skilling, or their opinion for that matter, I was just doing my thing on my own.
4- Create a registry erzats
Hashicorp maintains a humongous registry, hosting providers as well as modules. These resources are public. I happen to share a few public modules myself. But this may not be something you want to use in corporate environment. There could be multiple reasons for that, one of them being, you’re building modules too specific for your infrastructure which 1- makes them unusable for anybody else, and 2- would expose critical information about your architecture.
So without Terraform Cloud (a.k.a TFC) nor Terraform Enterprise (a.k.a TFE), how to manage reusable modules?
My take, is to create a dedicated Azure Devops Project, then create a repository per module. This way, you can version your modules individually using tags in the source attribute when calling a module. Some would argue it’s better/easier to have one repo with all your module, I’d say, everyone is entitle to his own opinion :p
Now, by doing so, instead of keeping a copy of my modules in each terraform project, and dealing with the pain to update them everywhere, I can reference a remote module with a url instead of a local path, and manage update by just changing tag where needed.
For example, instead of using having a multiple project like this, effectively duplicating those modules everywhere:
.
├── data.tf
├── main.tf
├── modules
│ ├── aks
│ ├── mysql
│ └── vnet
├── provider.tf
└── variables.tf
Using the source path below
module "vnet" {
source = "./modules/vnet"
(...redacted...)
}
I can leverage a git url and use the following:
module "vnet" {
source = "git::ssh://git@ssh.dev.azure.com/v3/myorganization/modules/vnet?ref=v1.7.0"
(...redacted...)
}
I don’t need to copy my vnet, aks and mysql modules in every project where I use them, I just use the remote repository and terraform will pull them at init phase.
You’ll find many blogs about terraform modules showcasing the above local modules path. They focus on explaining the code reusability within a single project, which is great to help grasp the concep of reusable modules. But ultimately, this fails to show how you can leverage the same module in multiple project, using a centralized module registry (i.e. remote repositories) which it where its real value resides.
About git path with ssh: You’ll notice the git url is an ssh one. This is because when using private repository, you have to authenticate to be able to pull the repository. When using on pipeline agent, the easy (and ugly) way to make it work, is to use an ssh key as a secure file and retrieve this key in a pipeline stage before initializing terraform folder.
5- keep it DRY! - pipeline stages templates
So things were starting to play together, and I have to be honest, I felt kinda awesome with my blooming IaC platform. But soon, something started to bother me. Isn’t there a way to avoid duplicating the pipeline definition yaml files?
After all, I just bored you to death with my obsession to keep it dry with modules.
TLDR; of course there is a solution.
We can rely on pipeline resources (more on that here). More specifically repositories resources allow you to retrieve pipelines templates from another repository (even in another project).
And just like with terraform modules, this left me with the task of making pipelines minimalist with only project specific settings, reusing stages, tasks and jobs defined in a centralized repository.
A small block in the yaml definition like this, and you can use any yaml stored in the terraform-stages-templates repository as a template:
resources:
repositories:
- repository: templates
project: pipelines
type: git
name: terraform-stages-templates
pretty handy!
I’m sure there are tons of other ways to use both templating and pipeline resources, but this was already a game changer to help me scale the solution.
6- Second attempt: onboard people
Now that there was a code base, versioned modules, templated piplines, etc., I needed to onboard people. But how to bring them to the project while they are familiar with neither terraform, nor git?
It was fun for the time it lasted but I couldn’t indefinitely play alone in my corner. This is not some nerd side project, this is the foundation of a corporate cloud project. Inevitably the skill gap issue would arise. I mean, I’m no genius, but if I’m left alone doing all that stuff it’s because nobody else had neither, the time, nor the skills, so I got paid to be the guy in the jungle advancing alone with his machete (try to picture me in a jungle with a machete and get a laugh ^^).
At this point, my research led me to a video from Ned Bellavance about json manipulation (lots of stuff like for loops, the discovery of the super useful terraform console among other things). Anyway, this was my Eureka moment: “everyone in the team has scripting experience to some extent. They don’t know terraform, few of them use git, but all of them understand the structure of a json file”. That was it, I would move the data input into json files so it’s agnostic from terraform, and my tf code would process it.
I was left with the second issue. Where to store these json until they get familiar with git? Enters Azure Storage Account. A General Purpose account, using blob storage would bring me versioning, and could be manipulated using cli or portal. So nothing disruption in the team’s usual tooling or workflow.
Finally remained the triggering of the pipeline. Azure pipelines trigger revolve around stuff happening within devops, like manual trigger using UI and commit (either direct or mege) trigger. However, I had no tool at disposal within Azure Devops to monitor what’s happening to some blob storages. But wait. It’s azure.
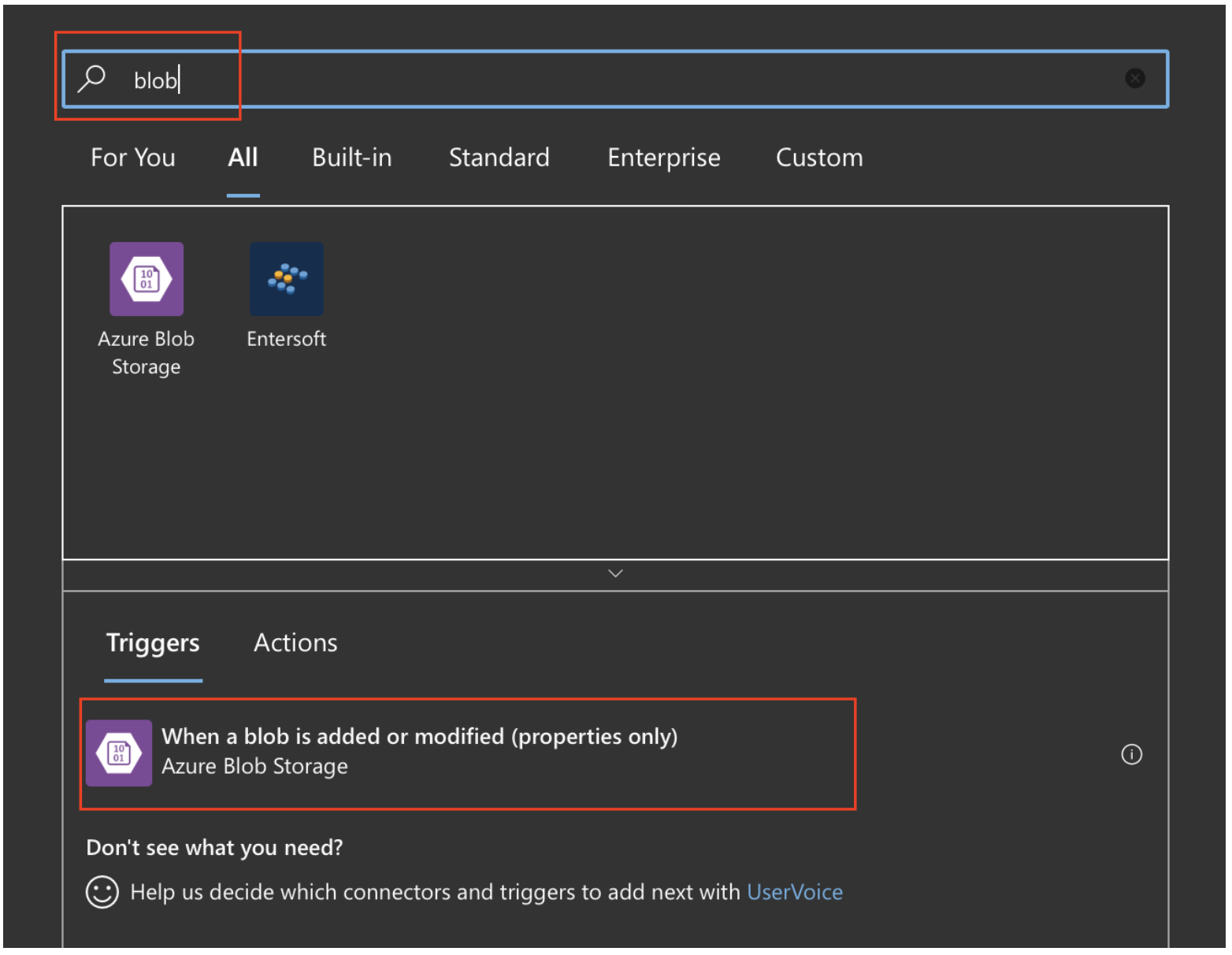
We have solutions for event driven automation! My solution appeared to be Logic Apps. Logic Apps can be triggered by several events from your platform, and you guessed it, change in blob is one of them.
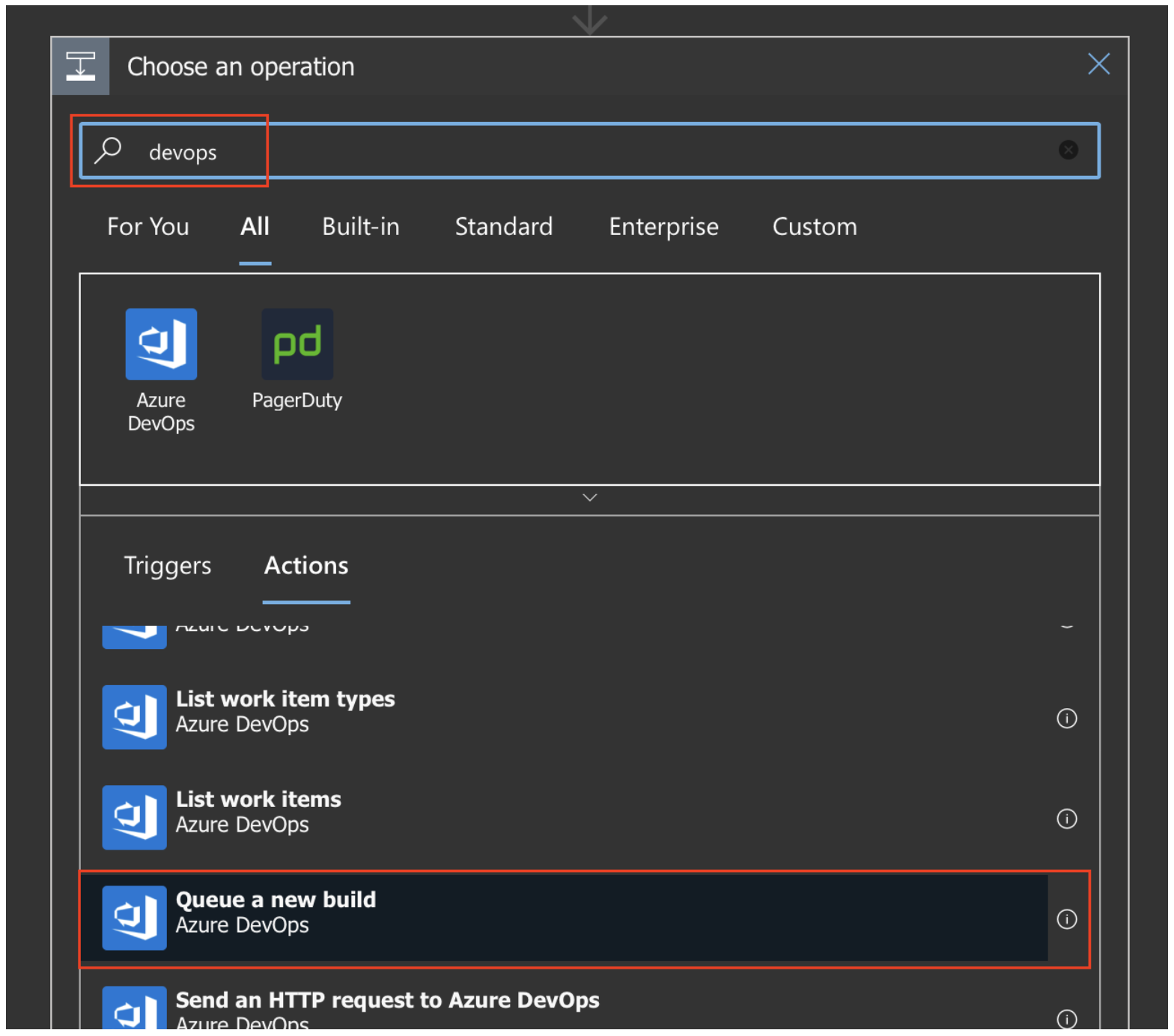
And as action, we can trigger azure devops build job. Perfect.
And that’s pretty much it.
Now the team can access the paramaters in the form of a json file, and it will trigger an azure devops build pipeline. On the other hand, I can keep using my git workflow for any terraform codebase modification. The PR will still trigger the same pipeline. I just had to update the artifact between plan and apply stages. Instead of copying only the tfplan, I had to retrieve the blob with all necessary json files for the running project.
And here is a recap of the situation. Not perfect, but pretty neat considering the constraints:
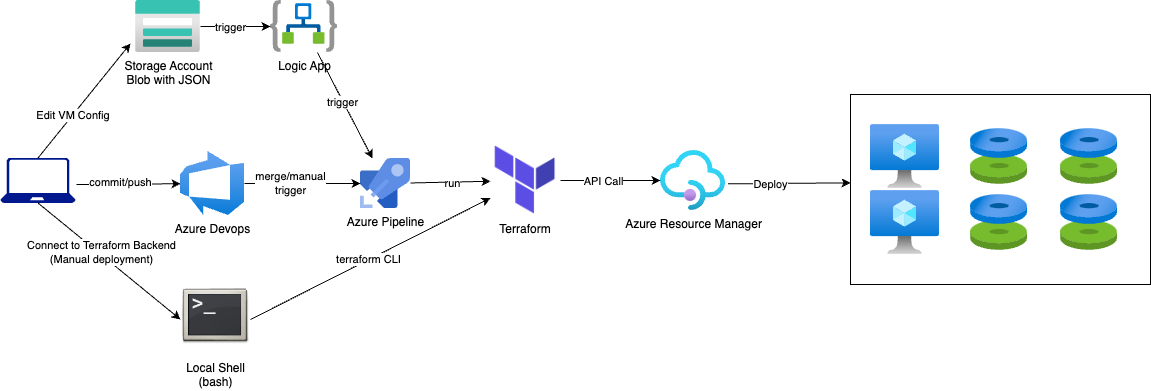
7- Adopt VCS(git) workflow
The above workflow lasted for several months. It gave us time to hire a few more people and start training the team to use terraform both from local terminal for new project, as well as the automated workflow with merge commit as trigger.
We repatriated the json(s) into their respective repositories once we had people confortable enough using Git.
And so the workflow slightly changed (streamlined):
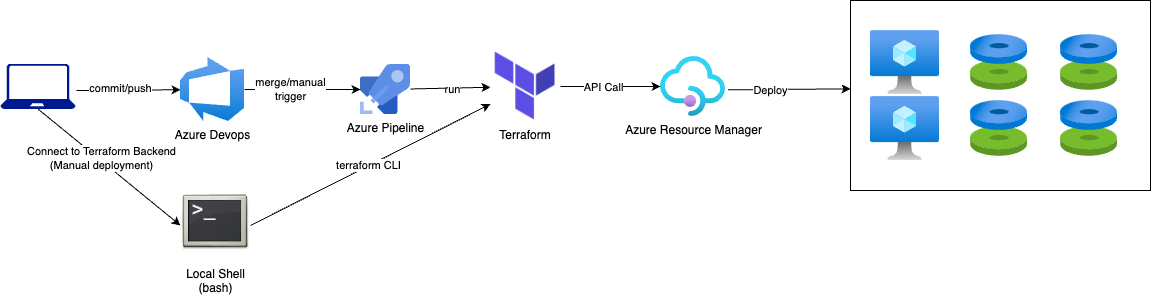
But as usual, I wanted more.
I mean, sure it wasn’t that bad at this point, but checking potential complementary tools for the TF workflow, I stumble upon infracost. And boy did I get envious. You see, infracost in its bare minimum form allows you to generate costs estimate from a terraform folder (i.e containing hcl files). But they also provide an extension to generate these cost estimations as comments in Azure Devops’s Pull Request. This got me into this obsession to have my terraform plan at the same place. In the PR. I mean, it’s litterally where it should be. That way, we have the history of all PR and their effect on the infrastructure.
And here I was, back on google, stackoverflow, blogs etc., looking for someone having done it already. I found this guy. The only issue for me is that I don’t use powershell, and all my tasks are bash shell based, running on linux agents. Long story short, I decided to leverage the azure devops API directly from the devops agent shell. I’ll explain this in detail in a future post.
And now, the pipelines look like below.
A build is triggered by the creation of the Pull Request, stopping after plan stage:
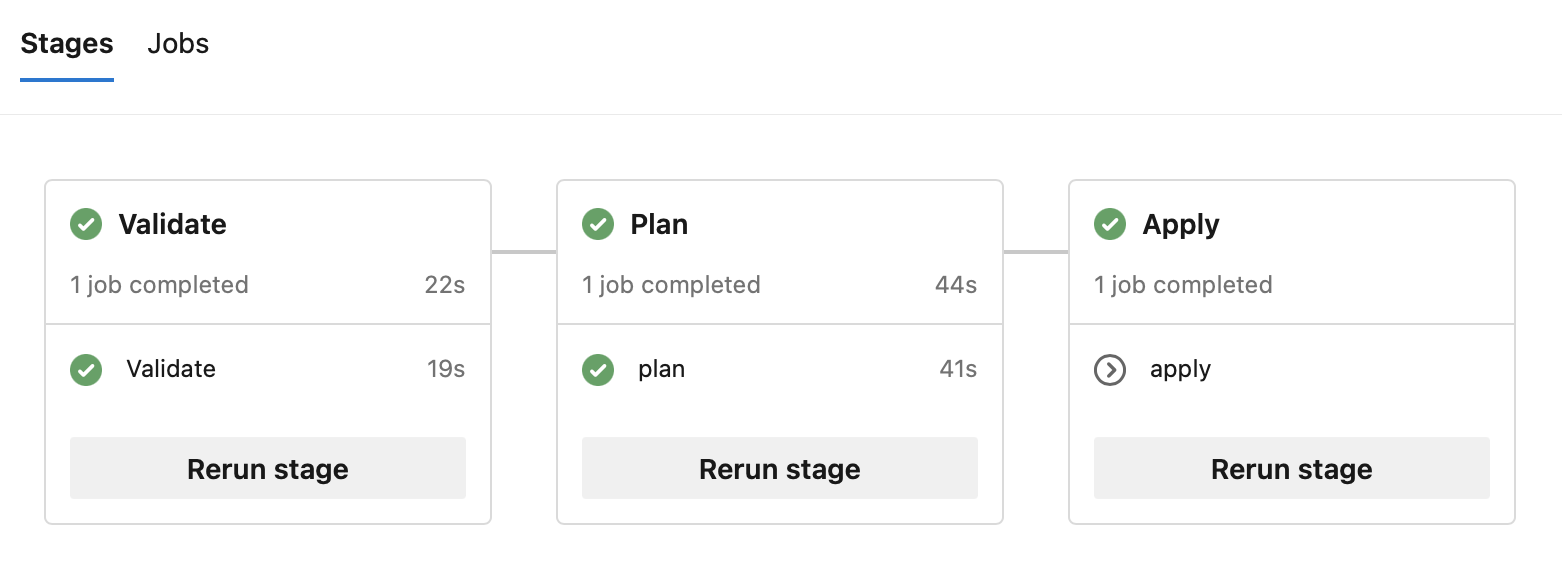
Then a comment is added to said PR:
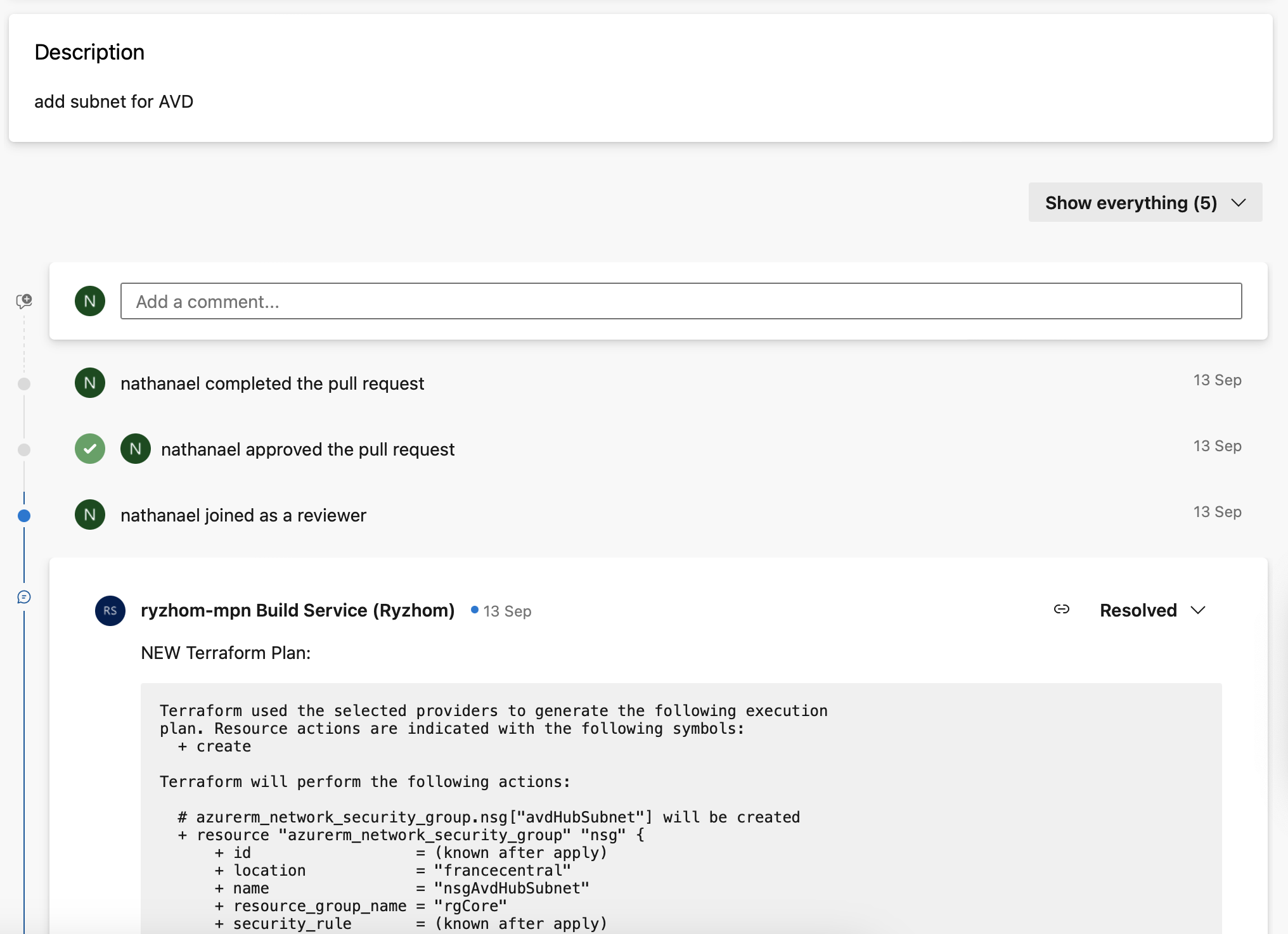
When comment resolved and PR approved, the pipeline re-runs, but skips plan and apply instead:
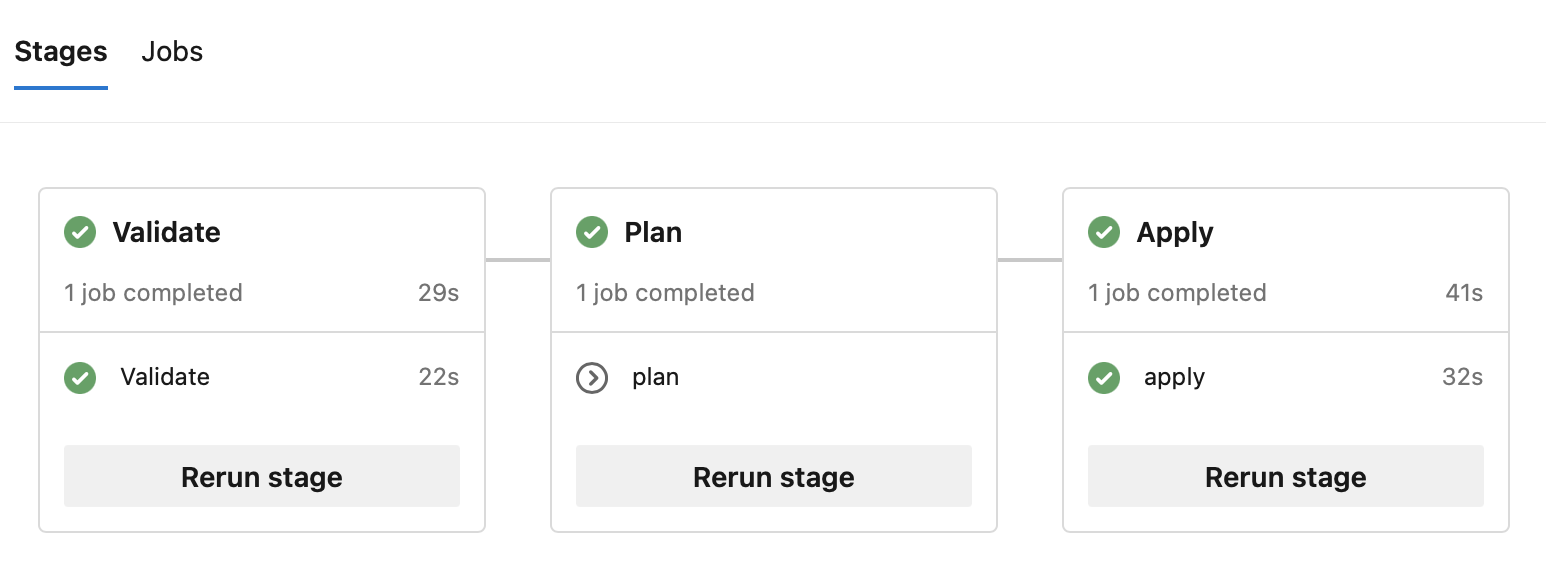
So no more awkward manual validation task with email notification. The validation is part of the PR process.
Now, to be fully transparent, I’m actually working on bringing back the manual validation task into this workflow. I want to be able to manually trigger the pipeline for several reasons, and this gives me the control to chose whether or not I should proceed with apply. Particularily useful to check potentiel drifts either in a scheduled fashion or arbitrarily.
8- Conclusion
Congratulation, you’ve read until here. This is my journey with Terraform, and it’s not ending there. Yours might differ, but I certainly hope this story could help you build your own solution. In the next articles we will dive into each stage of this journey, looking at the actual configurations involved