Terraform templating - json parsing !
Introduction
After playing with terraform for a while, I came to realize two things:
- I didn’t like the idea to have to change my code to adjust settings on my infrastructure
- I needed to ensure terraform managed infrastructure was not modified outside terraform.
Well part of the answer to the first problem is modules. You can check out my other post about them on this very site. But even then, having to play with my variables and/or my locals just didn’t cut it for me. I wanted something less impacting on the code and keep it as DRY as I could.
The other point is also a problem many of you, readers, may (have) face(d): ot everyone in the team or organization is trained with Terraform and HCL. What happens when only 1 or 2 contributors can amend the code of your infrastructure but you need fast changes? As good as they may be, your few terraform contributors become bottlenecks. And nobody wants bottleneck in our fast pace industry.
The solution I came up with is summed up with 3 main things:
- for loops
- jsondecode() function
- for_each meta-argument
Why JSON
First of all json, is machine friendly. HCL is actually said to be json compatible, but more human readable. How convinient ! :)
Json is also well know to most IT professional, at least to those doing scripting, automation or other sort of programming (and if you’re here, you’re probably one of us!).
Json is what you want it to be. Really. You can create all sort of key-value objects, value being of any type (string, boolean, list… you name it). Guess what, Azure API returns Json objects when asked about a resource. And that’s what Azure’s native ARM Templates uses to create resources.
In addition, Terraform provide some nifty native function to encode/decode json with jsonencode()and jsondecode(). All the more reasons to have a closer look at what json can do for us.
Templates
Templating is a powerfull thing. It’s an attempt to make sure standards are met, but at the same time, leave enough flexibility so that people may use it for their personnal needs. You should start to see where I’m going with al this: separate code and configuration.
| Code | Configuration |
|---|---|
| - terraform files | - json files |
| - fixed settings (enforcing standars) | - environment/application specific configurations |
Let’s dive into this idea with a myvm.json as an example.
{
"myVm":{
"size":"Standard_D2s_v3",
"vmAdminName":"localadm",
"publisher":"Canonical",
"offer":"0001-com-ubuntu-server-focal",
"sku":"20_04-lts-gen2",
"version":"latest",
"subnet":"mySubnet",
"zone":"1",
"osDiskSize":"64"
}
}
Then your terraform code could look something like that:
disclaimer:
this is incomplete and non-tested code just here to make a point. We’ll get to the real stuff later, so bear with me.
locals {
myVm = jsondecode(file("myvm.json"))
}
Which will be interpreted like so:

You then use your local data in your code:
resource "azurerm_linux_virtual_machine" "vm" {
name = keys(local.myVm)[0]
computer_name = keys(local.myVm)[0]
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
size = local.myVm["myVm"].size
admin_username = local.myVm["myVm"].vmAdminName
admin_password = "imabadpersonwhosetpasswordmanually"
disable_password_authentication = "false"
network_interface_ids = [
azurerm_network_interface.vmNic0.id,
]
boot_diagnostics {
storage_account_uri = azurerm_storage_account.vmDiag.primary_blob_endpoint
}
identity {
type = "SystemAssigned"
}
os_disk {
name = "${keys(local.myVm)[0]}OsDisk"
caching = "ReadWrite"
storage_account_type = "Standard_LRS"
disk_size_gb = local.myVm["myVm"].osDiskSize
}
source_image_reference {
publisher = local.myVm["myVm"].publisher
offer = local.myVm["myVm"].offer
sku = local.myVm["myVm"].sku
version = local.myVm["myVm"].version
}
zone = local.myVm["myVm"].zone
}
If you’re wondering what
keys(local.myVm)[0]is doing, it’s just to retrieve the vm name as a string from the map. Don’t get hung up on it, we’ll get rid of it by the end of this post.

Now you can let someone uninitiated to terraform deal with configuration change, by allowing him to modify the json only.
But we’re still missing a big piece of the puzzle.
- First there’s no way we stay DRY if we procede like the above example. You’d have to copy/paste your Terraform code for each (hint here!) json file, and have a json file for each VM. Not very effective.
- Second, how do you manage a json with multiple VM described inside, and, going further would it be possible to manage data disks in the same json file?
Well the answer is YES, obviously. But we’ll have to work some more to make it happen.
As a side note, you may have noticed the syntax
local.myVm["myVm"].<attribute_name>which is gives a hint of how terraform manages json data in a local.
For_each and for loops
In a previous post (about modules) we’ve seen a use case of the for_eachmeta-argument in order to keep code DRY. The same principle will apply in this use case. We can use for_each to avoid repeating our tf code.
Using the same sample as above, we can now instantiate many VMs using the same json file, by repeating the same construct multiple times in the json file, like so:
{
"myVm":{
"size":"Standard_D2s_v3",
"vmAdminName":"localadm",
"publisher":"Canonical",
"offer":"0001-com-ubuntu-server-focal",
"sku":"20_04-lts-gen2",
"version":"latest",
"subnet":"mySubnet",
"zone":"1",
"osDiskSize":"64"
}
},
{
"myOtherVm":{
"size":"Standard_B1ms",
"vmAdminName":"localadm",
"publisher":"Canonical",
"offer":"0001-com-ubuntu-server-focal",
"sku":"20_04-lts-gen2",
"version":"latest",
"subnet":"mySubnet",
"zone":"2",
"osDiskSize":"64"
}
}
As you can see, we keep the same structure for each vm definition, but we can use different values for their attributes. To make use of this new configuration, check the code below:
resource "azurerm_network_interface" "vmNic0" {
for_each = local.myVm
name = each.key
location = "westeurope"
resource_group_name = azurerm_resource_group.rg.name
ip_configuration {
name = "internal"
subnet_id = azurerm_subnet.subnet.id
private_ip_address_allocation = "Dynamic"
}
}
resource "azurerm_linux_virtual_machine" "vm" {
for_each = local.myVm
name = each.key
computer_name = each.key
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
size = each.value.size
admin_username = each.value.vmAdminName
admin_password = "Imabadpers0nwh0setpassw0rdmanually"
disable_password_authentication = "false"
network_interface_ids = [
azurerm_network_interface.vmNic0[each.key].id,
]
boot_diagnostics {
storage_account_uri = azurerm_storage_account.vmDiag.primary_blob_endpoint
}
identity {
type = "SystemAssigned"
}
os_disk {
name = "${each.key}OsDisk"
caching = "ReadWrite"
storage_account_type = "Standard_LRS"
disk_size_gb = each.value.osDiskSize
}
source_image_reference {
publisher = each.value.publisher
offer = each.value.offer
sku = each.value.sku
version = each.value.version
}
zone = each.value.zone
}
Ok, great, we are now able to instantiate as many vm as we want with the same code, by just defining VM configuration in the json. Cool. But wouldn’t it be great to manage data disks the same way?
For loop
We could just make up a second file with data disks information, a mydisks.jsonif you will. But then you’d have to manually reference each disk with his virtual machine, and we don’t like doing things manually because it generates error eventually. We’re only human after all ^^
But hey, what is preventing us from doing it in the same json and manage dependency like below ?
{
"myVm":{
"size":"Standard_D2s_v3",
"vmAdminName":"localadm",
"publisher":"Canonical",
"offer":"0001-com-ubuntu-server-focal",
"sku":"20_04-lts-gen2",
"version":"latest",
"subnet":"mySubnet",
"zone":"1",
"osDiskSize":"64",
"disks":[
{
"lunId":"1",
"size":"128"
},
{
"lunId":"2",
"size":"128"
}
]
},
"myOtherVm":{
"size":"Standard_B1ms",
"vmAdminName":"localadm",
"publisher":"Canonical",
"offer":"0001-com-ubuntu-server-focal",
"sku":"20_04-lts-gen2",
"version":"latest",
"subnet":"mySubnet",
"zone":"2",
"osDiskSize":"64",
"disks":[
{
"lunId":"1",
"size":"32"
}
]
}
}
We can build a local with the informations for the disks, but we need the vm name to go with it. That’s where using for loops will help us.
You have to consider a few things:
- if your loop is inside brackets [], the result will be a list
- if your loop is inside braces {}, the resul will be a map (that means you have to provide a key for you map)
The most useful tool at your disposal to play with for loops and building locals from json is terraform console. In the console, you can use all native functions you want to try and test transforming your data. Ned Bellavance has a great video on the for loops I strongly suggest anyone instrested to watch.
The tricky part is that you will have to nest for loops to get what you want. Like so:
vmData = jsondecode(file("myVm.json"))
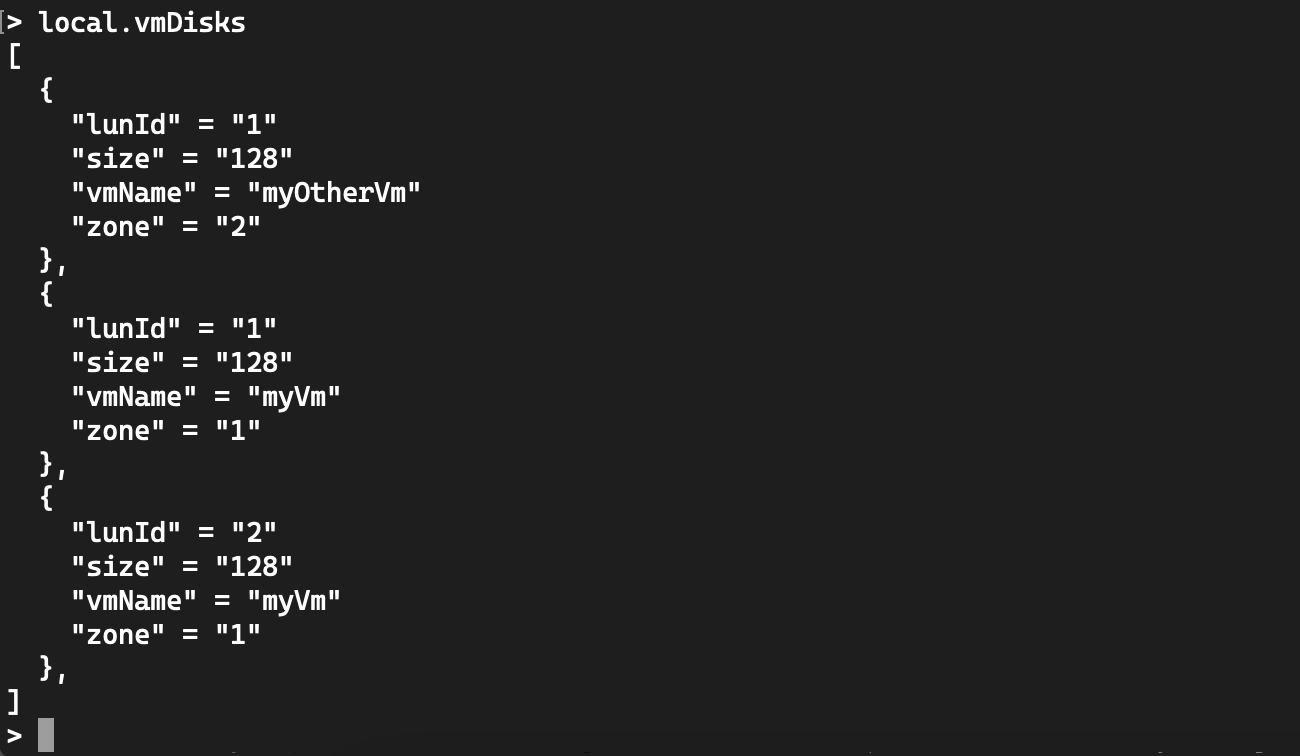
vmDisks = flatten([
for vm_key, vm in local.vmData : [
for i in vm.disks :
{
size = i.size,
lunId = i.lunId,
vmName = vm_key,
zone = vm.zone
}
]
])
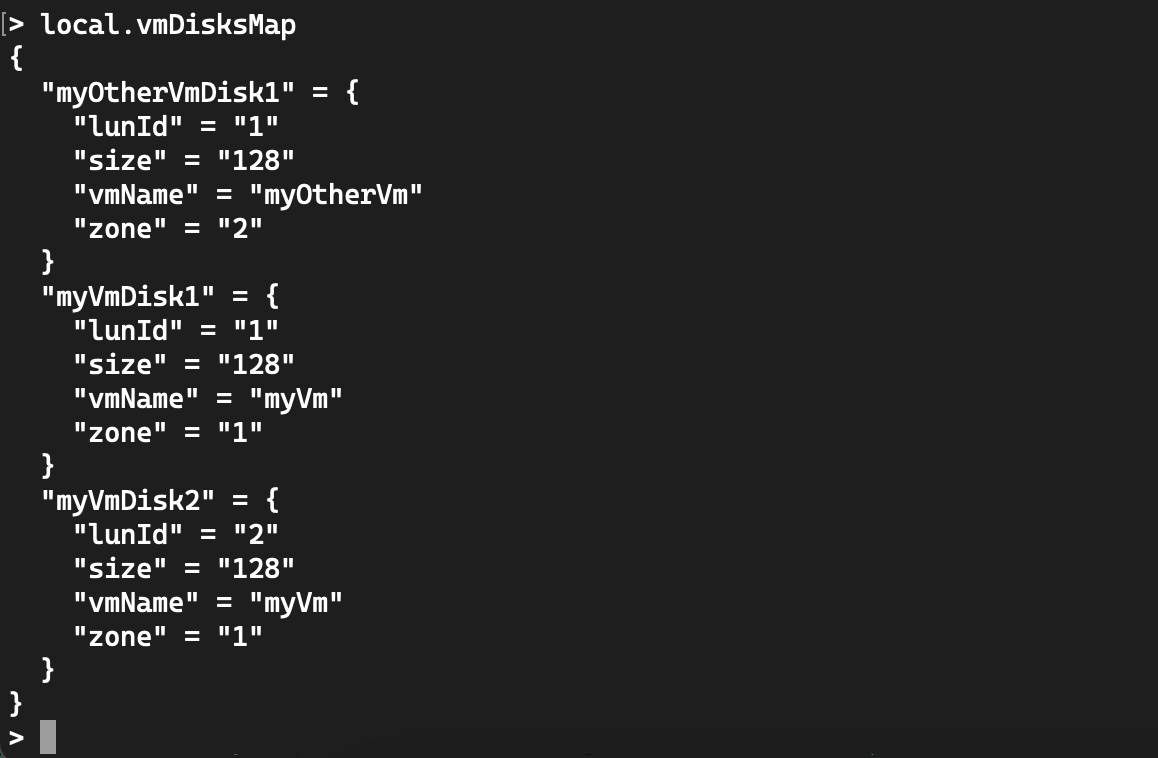
vmDisksMap = {
for k, v in local.vmDisks :
"${v.vmName}Disk${title(v.lunId)}" => {
lunId = v.lunId,
size = v.size,
vmName = v.vmName,
zone = v.zone
}
}
Let’s have a look at how terraform interpretes these locals, by using terraform console (we’ll skip vmData as it will just take the whole json and convert it in an hcl object just like we’ve seen in the Templates section of this post):
The first local makes a list from the original json disks section, but re-insert the vm name and its availability zone into the disks data. The nested for loops actually generate a list of lists so in order to get rid of the additionnal “level” we use the flatten() function:
Then, to transform this list into a map, we need to specify a key which will be used as the disk name:
Put it all together
Everything I showed here is available for use in a public repository on my github. You can clone it and play with it. If it suits your needs, I would suggest you make it your own by adding some naming convention with som prefixing or even use regex to ensure your standards are met.
Here is the link to the repository: GitHub
Below is an example to use it. Just replace vmDiag and myKv with globally unique names:
Generic code to meet requirements:
variable "vmDiag" {
default = "" # /!\ Name must be globally unique /!\
}
variable "myKv" {
default = "" # /!\ Name must be globally unique /!\
}
resource "azurerm_resource_group" "rg" {
name = "myRg"
location = "westeurope"
}
resource "azurerm_virtual_network" "vnet" {
name = "myVnet"
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
address_space = ["10.255.0.0/16"]
}
resource "azurerm_subnet" "subnet" {
name = "mySubnet"
virtual_network_name = azurerm_virtual_network.vnet.name
resource_group_name = azurerm_resource_group.rg.name
address_prefixes = ["10.255.0.0/24"]
}
resource "azurerm_storage_account" "vmDiag" {
name = var.vmDiag
location = "westeurope"
resource_group_name = azurerm_resource_group.rg.name
account_tier = "Standard"
account_replication_type = "LRS"
}
data "azurerm_client_config" "current" {}
resource "azurerm_key_vault" "myKv" {
name = var.myKv
location = "westeurope"
resource_group_name = azurerm_resource_group.rg.name
enabled_for_disk_encryption = true
tenant_id = data.azurerm_client_config.current.tenant_id
soft_delete_retention_days = 7
purge_protection_enabled = false
sku_name = "standard"
access_policy {
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = data.azurerm_client_config.current.object_id
key_permissions = [
"Backup", "Create", "Decrypt", "Delete", "Encrypt",
"Get", "Import", "List", "Purge", "Recover",
"Restore", "Sign", "UnwrapKey", "Update", "Verify", "WrapKey"
]
secret_permissions = [
"Backup", "Delete", "Get", "List", "Purge", "Recover", "Restore", "Set"
]
storage_permissions = [
"Backup", "Delete", "DeleteSAS", "Get", "GetSAS",
"List", "ListSAS", "Purge", "Recover", "RegenerateKey",
"Restore", "Set", "SetSAS", "Update"
]
}
}
Module usage example:
module "vm" {
source = "github.com/nfrappart/azTerraVmLinuxAvZoneJsonPool?ref=v1.0.0"
configFileName = "myvm.json"
rgName = "myProject"
env = "prod"
keyVault = azurerm_key_vault.myKv.name
keyVaultRg = azurerm_resource_group.rg.name
vmDiagSta = azurerm_storage_account.vmDiag.name
rgVmDiagSta = azurerm_resource_group.rg.name
vnetName = azurerm_virtual_network.vnet.name
vnetRg = azurerm_resource_group.rg.name
# explicit dependencies below are only required if the resources don't exist before hand
depends_on = [
azurerm_key_vault.myKv,
azurerm_subnet.subnet
]
}